GraphQL API
GraphQL API 允许执行查询和突变,以通过 Strapi 的 GraphQL 插件 与 content-types 进行交互。结果可以是 filtered、sorted 和 paginated。
¥The GraphQL API allows performing queries and mutations to interact with the content-types through Strapi's GraphQL plugin. Results can be filtered, sorted and paginated.
要使用 GraphQL API,请安装 GraphQL 插件:
¥To use the GraphQL API, install the GraphQL plugin:
- Yarn
- NPM
yarn add @strapi/plugin-graphql
npm install @strapi/plugin-graphql
安装后,可通过 /graphql URL 访问 GraphQL 在线运行,并可用于以交互方式构建查询和修改,以及阅读针对你的内容类型量身定制的文档:
¥Once installed, the GraphQL playground is accessible at the /graphql URL and can be used to interactively build your queries and mutations and read documentation tailored to your content-types:
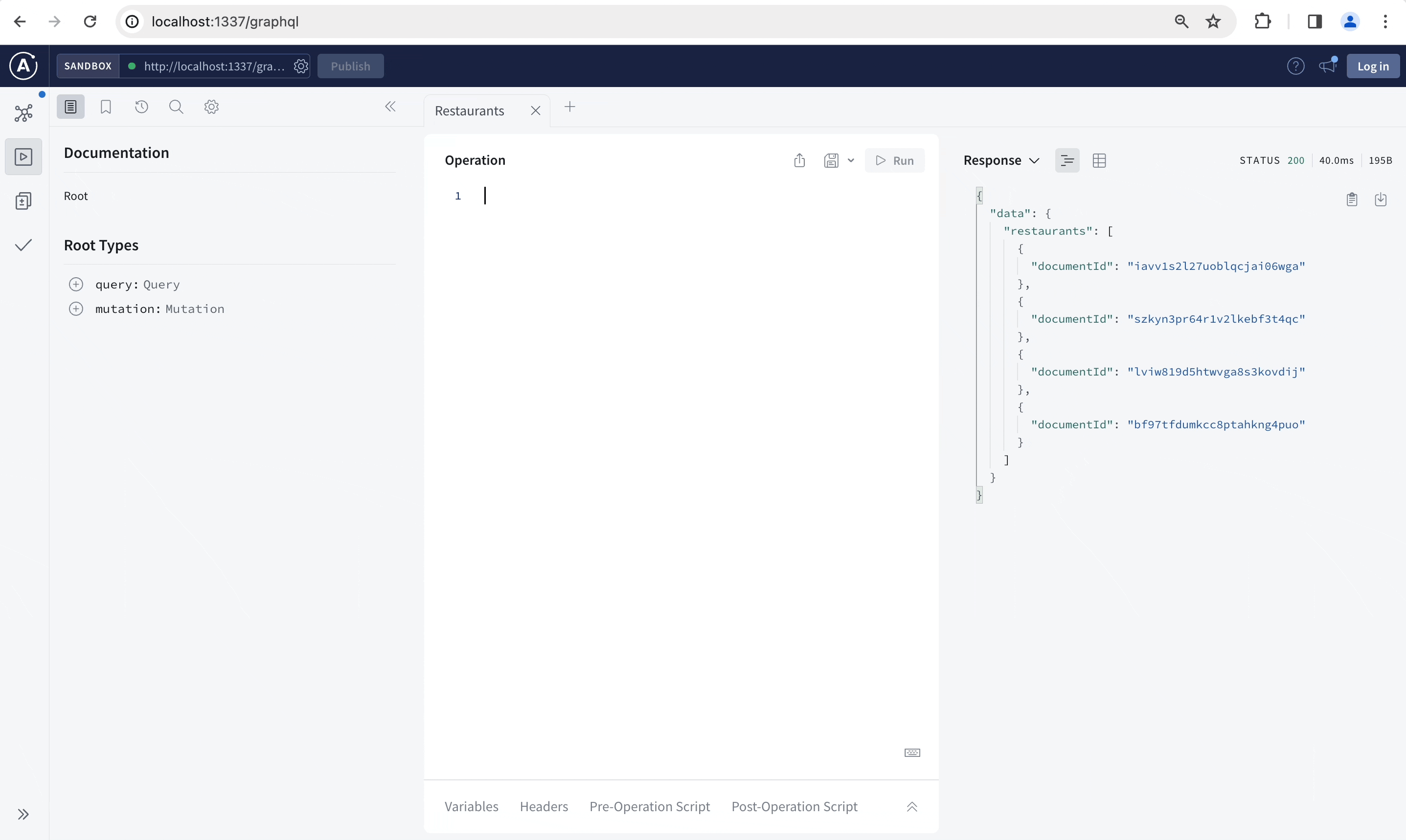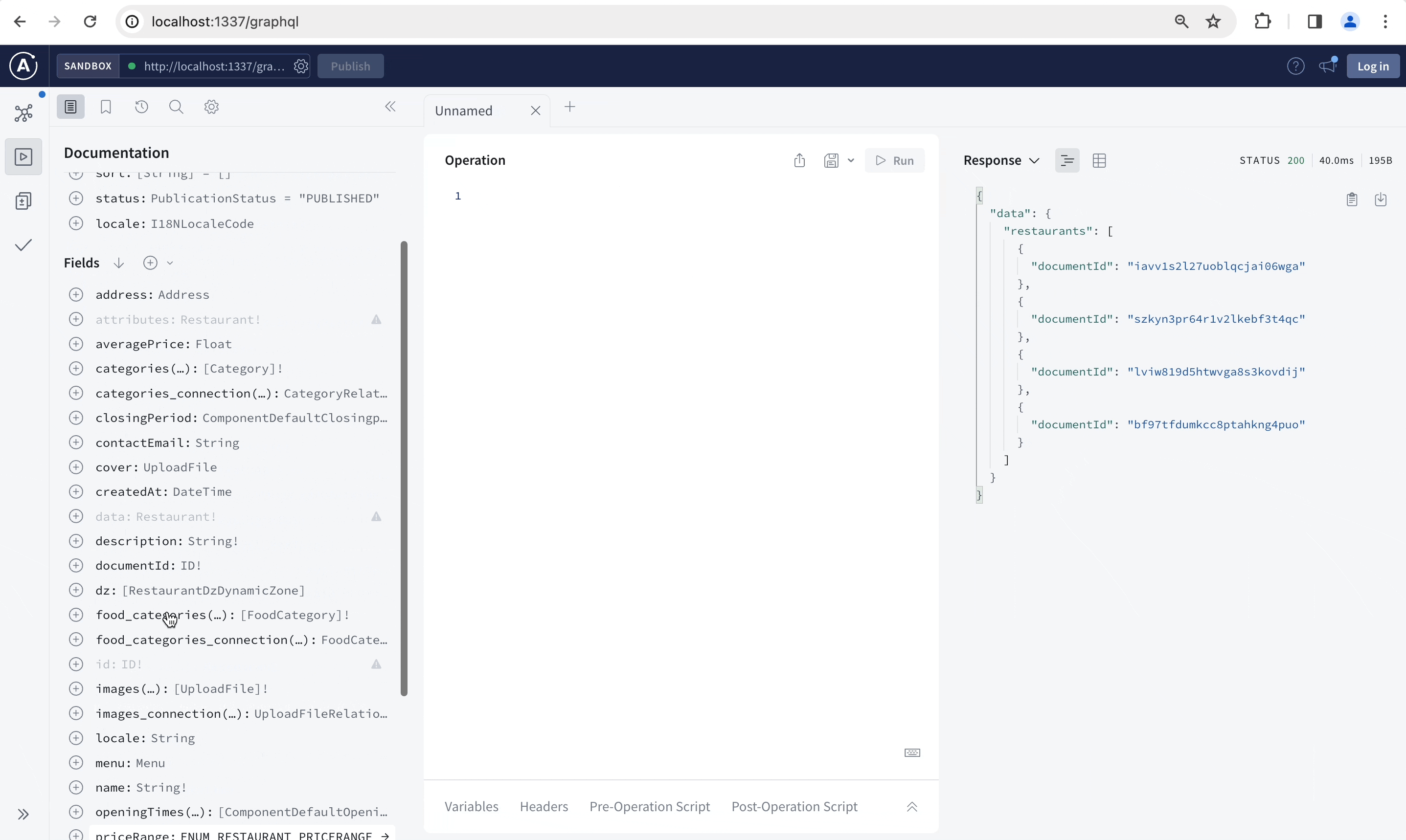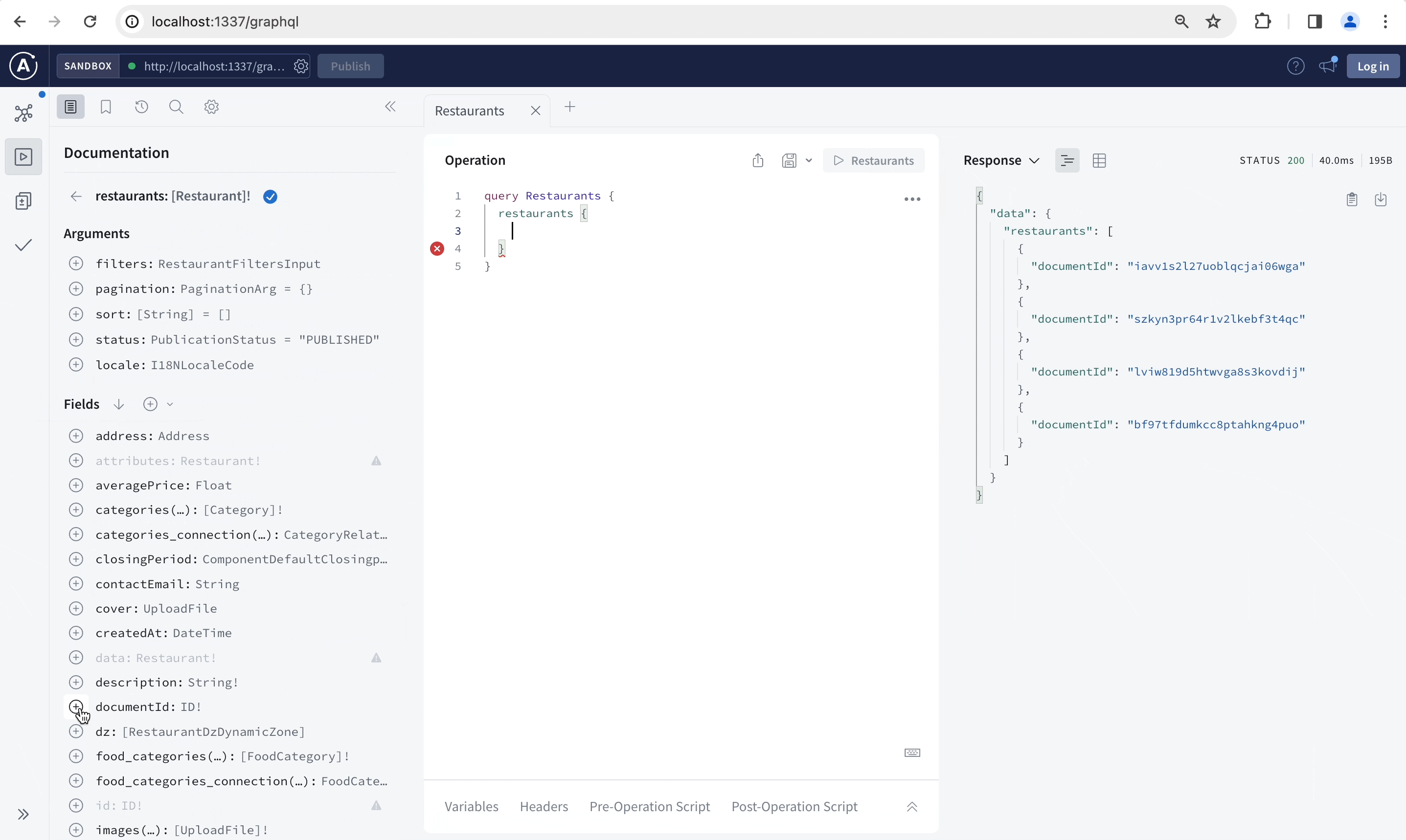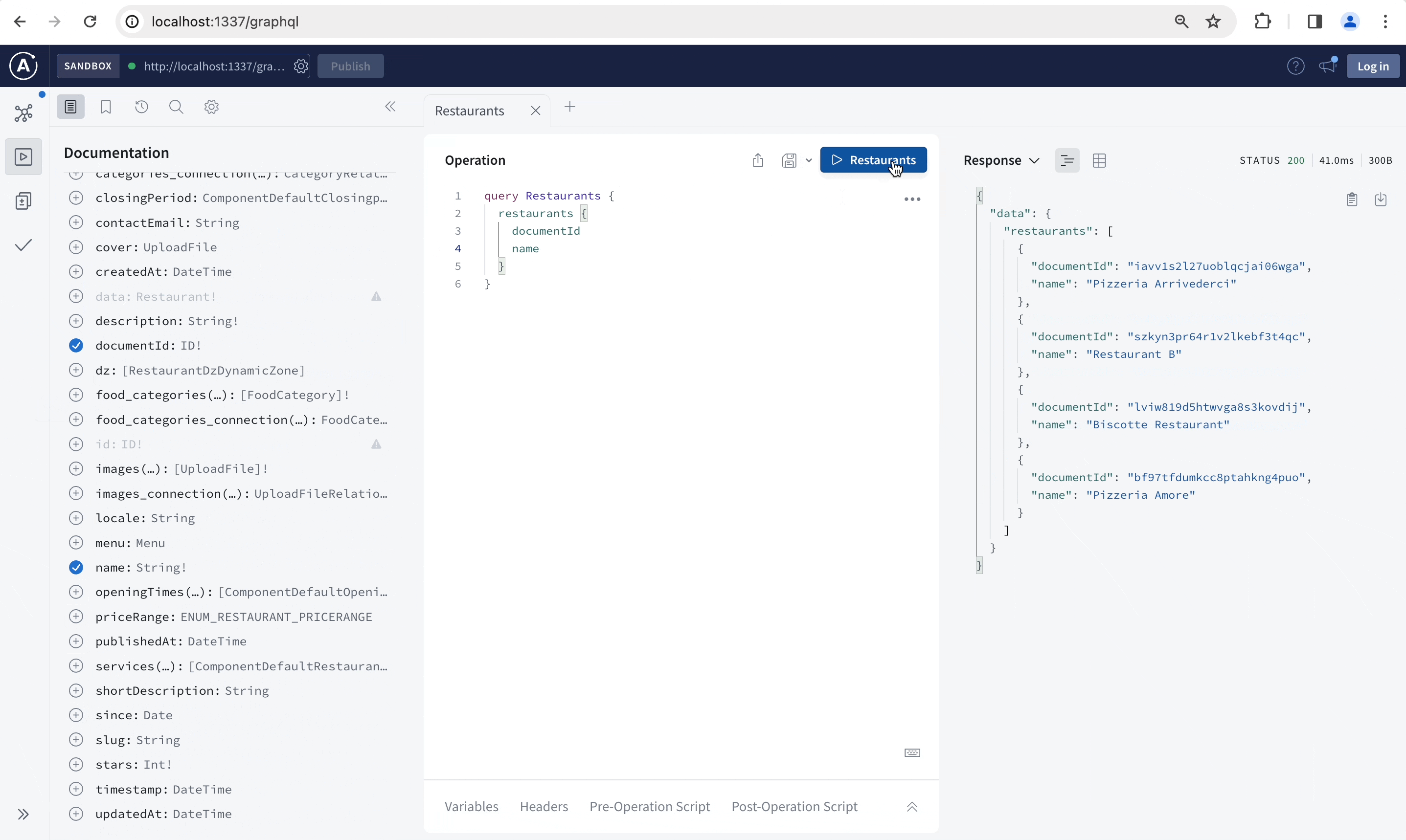
GraphQL API 不支持媒体上传。对所有文件上传使用 REST API POST /upload 端点,并使用返回的信息在内容类型中链接到它。你仍然可以使用媒体文件 id(参见 媒体文件的修改)更新或删除具有 updateUploadFile 和 deleteUploadFile 突变的上传文件。
¥The GraphQL API does not support media upload. Use the REST API POST /upload endpoint for all file uploads and use the returned info to link to it in content types. You can still update or delete uploaded files with the updateUploadFile and deleteUploadFile mutations using media files id (see mutations on media files).
查询
¥Queries
GraphQL 中的查询用于获取数据而不修改数据。
¥Queries in GraphQL are used to fetch data without modifying it.
当将内容类型添加到你的项目时,2 个自动生成的 GraphQL 查询将添加到你的架构中,以内容类型的单数和复数 API ID 命名,如下例所示:
¥When a content-type is added to your project, 2 automatically generated GraphQL queries are added to your schema, named after the content-type's singular and plural API IDs, as in the following example:
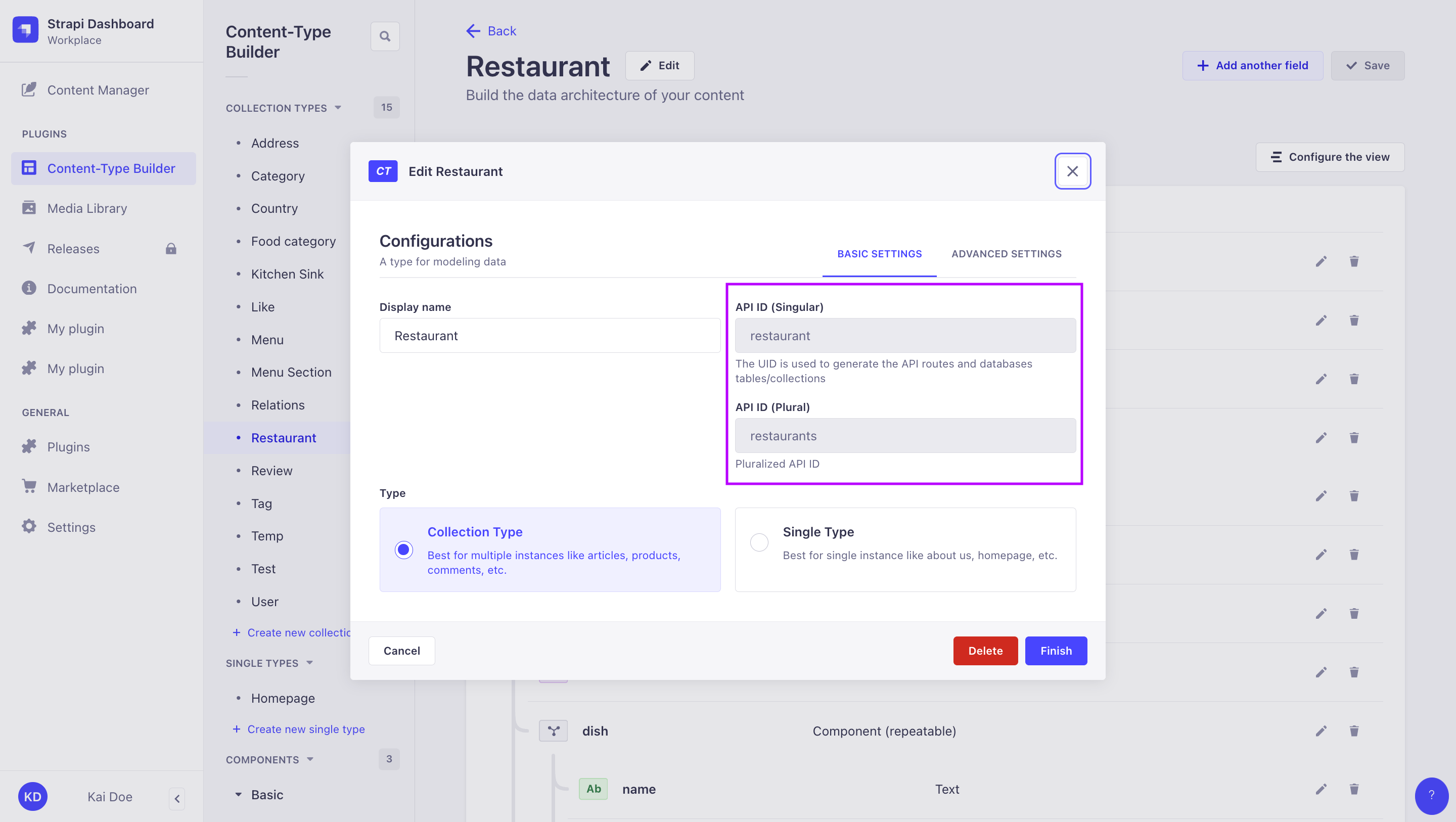
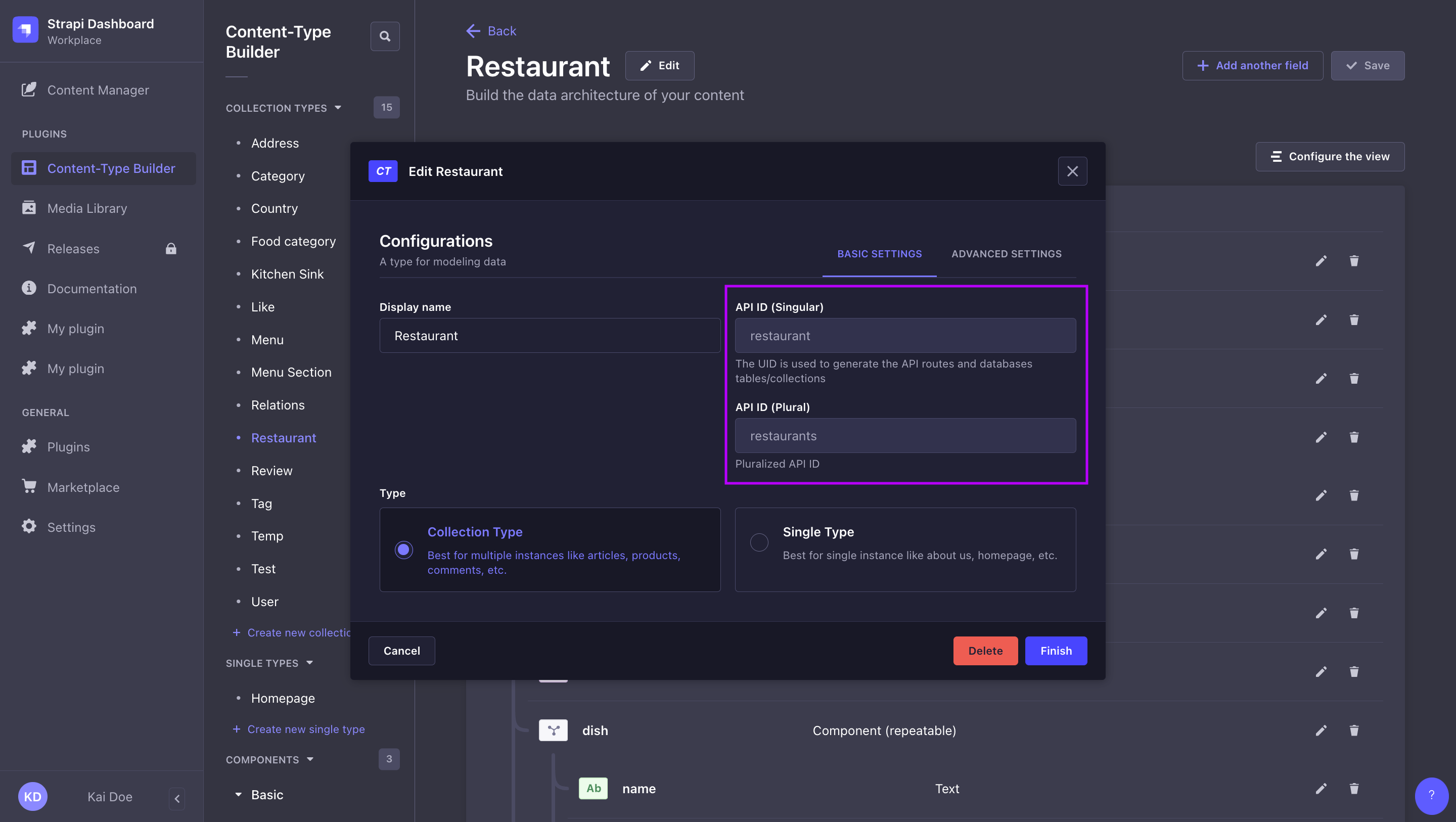
| 内容类型显示名称 | Singular API ID | 复数 API ID |
|---|---|---|
| 餐厅 | restaurant | restaurants |
Singular API ID vs. Plural API ID:
在 Content-Type Builder 中创建内容类型时定义单数 API ID 和复数 API ID 值,并且可以在管理面板中编辑内容类型时找到(参见 用户指南)。你可以在创建内容类型时定义自定义 API ID,但之后无法修改这些 ID。
¥Singular API ID and Plural API ID values are defined when creating a content-type in the Content-Type Builder, and can be found while editing a content-type in the admin panel (see User Guide). You can define custom API IDs while creating the content-type, but these can not modified afterwards.
获取单个文档
¥Fetch a single document
文档 可以通过其 documentId 获取。
¥Documents can be fetched by their documentId.
{
restaurant(documentId: "a1b2c3d4e5d6f7g8h9i0jkl") {
name
description
}
}
获取多个文档
¥Fetch multiple documents
要获取多个文档 ,你可以使用简单的扁平查询或 中继样式 查询:
¥To fetch multiple documents you can use simple, flat queries or Relay-style queries:
- Flat queries
- Relay-style queries
要获取多个文档,你可以使用如下所示的扁平查询:
¥To fetch multiple documents you can use flat queries like the following:
restaurants {
documentId
title
}
关系也可以通过文档服务 API 连接、断开和设置,就像 REST API 一样(有关示例,请参阅 )。
¥Relay-style queries can be used to fetch multiple documents and return meta information:
{
restaurants_connection {
nodes {
documentId
name
}
pageInfo {
pageSize
page
pageCount
total
}
}
}
获取关系
¥Fetch relations
你可以要求在扁平查询或 中继样式 查询中包含关系数据:
¥You can ask to include relation data in your flat queries or in your Relay-style queries:
- Flat queries
- Relay-style queries
以下示例从 "餐厅" 内容类型中获取所有文档,并且对于每个文档,还返回与 "类别" 内容类型的多对多关系的一些字段:
¥The following example fetches all documents from the "Restaurant" content-type, and for each of them, also returns some fields for the many-to-many relation with the "Category" content-type:
{
restaurants {
documentId
name
description
# categories is a many-to-many relation
categories {
documentId
name
}
}
}
以下示例使用 Relay 样式查询从 "餐厅" 内容类型中获取所有文档,并且对于每个餐厅,还返回与 "类别" 内容类型的多对多关系的一些字段:
¥The following example fetches all documents from the "Restaurant" content-type using a Relay-style query, and for each restaurant, also returns some fields for the many-to-many relation with the "Category" content-type:
{
restaurants_connection {
nodes {
documentId
name
description
# categories is a many-to-many relation
categories_connection {
nodes {
documentId
name
}
}
}
pageInfo {
page
pageCount
pageSize
total
}
}
}
目前,pageInfo 仅适用于第一级文档。Strapi 的未来实现可能会为关系实现 pageInfo。
¥For now, pageInfo only works for documents at the first level. Future implementations of Strapi might implement pageInfo for relations.
Possible use cases for pageInfo:
这有效:
¥This works:
{
restaurants_connection {
nodes {
documentId
name
description
# many-to-many relation
categories_connection {
nodes {
documentId
name
}
}
}
pageInfo {
page
pageCount
pageSize
total
}
}
}
这不起作用:
¥This does not work:
{
restaurants_connection {
nodes {
documentId
name
description
# many-to-many relation
categories_connection {
nodes {
documentId
name
}
# not supported
pageInfo {
page
pageCount
pageSize
total
}
}
}
pageInfo {
page
pageCount
pageSize
total
}
}
}}
获取媒体字段
¥Fetch media fields
媒体字段内容的获取方式与其他属性一样。
¥Media fields content is fetched just like other attributes.
以下示例从 "餐厅" 内容类型中获取附加到每个文档的每个 cover 媒体字段的 url 属性值:
¥The following example fetches the url attribute value for each cover media field attached to each document from the "Restaurants" content-type:
{
restaurants {
images {
documentId
url
}
}
}
对于多个媒体字段,你可以使用扁平查询或 中继样式 查询:
¥For multiple media fields, you can use flat queries or Relay-style queries:
- Flat queries
- Relay-style queries
以下示例从 "餐厅" 内容类型中的 images 多媒体字段中获取一些属性:
¥The following example fetches some attributes from the images multiple media field found in the "Restaurant" content-type:
{
restaurants {
images_connection {
nodes {
documentId
url
}
}
}
}
以下示例使用 Relay 样式从 "餐厅" 内容类型中找到的 images 多媒体字段中获取一些属性查询:
¥The following example fetches some attributes from the images multiple media field found in the "Restaurant" content-type using a Relay-style query:
{
restaurants {
images_connection {
nodes {
documentId
url
}
}
}
}
目前,pageInfo 仅适用于文档。Strapi 的未来实现也可能为媒体字段 _connection 实现 pageInfo。
¥For now, pageInfo only works for documents. Future implementations of Strapi might implement pageInfo for the media fields _connection too.
获取组件
¥Fetch components
组件内容的获取方式与其他属性一样。
¥Components content is fetched just like other attributes.
以下示例从 "餐厅" 内容类型中获取添加到每个文档的每个 closingPeriod 组件的 label、start_date 和 end_date 属性值:
¥The following example fetches the label, start_date, and end_date attributes values for each closingPeriod component added to each document from the "Restaurants" content-type:
{
restaurants {
closingPeriod {
label
start_date
end_date
}
}
}
获取动态区域数据
¥Fetch dynamic zone data
动态区域是 GraphQL 中的联合类型,因此你需要使用 fragments(即使用 ...on)来查询字段,并将组件名称(使用 ComponentCategoryComponentname 语法)传递给 __typename:
¥Dynamic zones are union types in GraphQL so you need to use fragments (i.e., with ...on) to query the fields, passing the component name (with the ComponentCategoryComponentname syntax) to __typename:
以下示例从 "默认" 组件类别中获取可添加到 "dz" 动态区域的 "Closingperiod" 组件的 label 属性的数据:
¥The following example fetches data for the label attribute of a "Closingperiod" component from the "Default" components category that can be added to the "dz" dynamic zone:
{
restaurants {
dz {
__typename
...on ComponentDefaultClosingperiod {
# define which attributes to return for the component
label
}
}
}
}
获取草稿或已发布版本
¥Fetch draft or published versions
如果内容类型启用了 起草并发布 功能,你可以向查询添加 status 参数以获取文档的草稿或已发布版本 :
¥If the Draft & Publish feature is enabled for the content-type, you can add a status parameter to queries to fetch draft or published versions of documents :
query Query($status: PublicationStatus) {
restaurants(status: DRAFT) {
documentId
name
publishedAt # should return null
}
}
query Query($status: PublicationStatus) {
restaurants(status: PUBLISHED) {
documentId
name
publishedAt
}
}
突变
¥Mutations
GraphQL 中的突变用于修改数据(例如创建、更新和删除数据)。
¥Mutations in GraphQL are used to modify data (e.g. create, update, and delete data).
当将内容类型添加到你的项目时,将向你的架构添加 3 个自动生成的 GraphQL 修改,用于创建、更新和删除文档 。
¥When a content-type is added to your project, 3 automatically generated GraphQL mutations to create, update, and delete documents are added to your schema.
例如,对于 "餐厅" 内容类型,将生成以下突变:
¥For instance, for a "Restaurant" content-type, the following mutations are generated:
| 使用案例 | Singular API ID |
|---|---|
| 创建一个新的 "餐厅" 文档 | createRestaurant |
| 更新现有的 "餐厅" 餐厅 | updateRestaurant |
| 删除现有的 "餐厅" 餐厅 | deleteRestaurant |
创建新文档
¥Create a new document
创建新文档时,data 参数将具有特定于你的内容类型的关联输入类型。
¥When creating new documents, the data argument will have an associated input type that is specific to your content-type.
例如,如果你的 Strapi 项目包含 "餐厅" 内容类型,你将获得以下内容:
¥For instance, if your Strapi project contains the "Restaurant" content-type, you will have the following:
| 修改 | 争论 | 输入类型 |
|---|---|---|
createRestaurant | data | RestaurantInput! |
以下示例为 "餐厅" 内容类型创建一个新文档并返回其 name 和 documentId:
¥The following example creates a new document for the "Restaurant" content-type and returns its name and documentId:
mutation CreateRestaurant($data: RestaurantInput!) {
createRestaurant(data: {
name: "Pizzeria Arrivederci"
}) {
name
documentId
}
}
创建新文档时,会自动生成 documentId。
¥When creating a new document, a documentId is automatically generated.
突变的实现还支持关系属性。例如,你可以创建一个新的 "类别" 并将许多 "餐厅"(使用它们的 documentId)附加到它,方法是编写如下查询:
¥The implementation of the mutations also supports relational attributes. For example, you can create a new "Category" and attach many "Restaurants" (using their documentId) to it by writing your query like follows:
mutation CreateCategory {
createCategory(data: {
Name: "Italian Food"
restaurants: ["a1b2c3d4e5d6f7g8h9i0jkl", "bf97tfdumkcc8ptahkng4puo"]
}) {
documentId
Name
restaurants {
documentId
name
}
}
}
如果为你的内容类型启用了国际化(i18n)功能,则可以为特定语言环境创建文档(请参阅 i18n 文档)。
¥If the Internationalization (i18n) feature is enabled for your content-type, you can create a document for a specific locale (see i18n documentation).
更新现有文档
¥Update an existing document
更新现有文档 时,传递包含新内容的 documentId 和 data 对象。data 参数将具有特定于你的内容类型的关联输入类型。
¥When updating an existing document , pass the documentId and the data object containing new content. The data argument will have an associated input type that is specific to your content-type.
例如,如果你的 Strapi 项目包含 "餐厅" 内容类型,你将获得以下内容:
¥For instance, if your Strapi project contains the "Restaurant" content-type, you will have the following:
| 修改 | 争论 | 输入类型 |
|---|---|---|
updateRestaurant | data | RestaurantInput! |
例如,以下示例从 "餐厅" 内容类型更新现有文档并为其指定新名称:
¥For instance, the following example updates an existing document from the "Restaurants" content-type and give it a new name:
mutation UpdateRestaurant($documentId: ID!, $data: RestaurantInput!) {
updateRestaurant(
documentId: "bf97tfdumkcc8ptahkng4puo",
data: { name: "Pizzeria Amore" }
) {
documentId
name
}
}
如果为你的内容类型启用了国际化(i18n)功能,则可以为特定语言环境创建文档(请参阅 i18n 文档)。
¥If the Internationalization (i18n) feature is enabled for your content-type, you can create a document for a specific locale (see i18n documentation).
更新关系
¥Update relations
你可以通过传递 documentId 或 documentId 数组(取决于关系类型)来更新关系属性。
¥You can update relational attributes by passing a documentId or an array of documentId (depending on the relation type).
例如,以下示例从 "餐厅" 内容类型更新文档,并通过 categories 关系字段向来自 "类别" 内容类型的文档添加关系:
¥For instance, the following example updates a document from the "Restaurant" content-type and adds a relation to a document from the "Category" content-type through the categories relation field:
mutation UpdateRestaurant($documentId: ID!, $data: RestaurantInput!) {
updateRestaurant(
documentId: "slwsiopkelrpxpvpc27953je",
data: { categories: ["kbbvj00fjiqoaj85vmylwi17"] }
) {
documentId
name
categories {
documentId
Name
}
}
}
删除文档
¥Delete a document
要删除文档 ,请传递其 documentId:
¥To delete a document , pass its documentId:
mutation DeleteRestaurant {
deleteRestaurant(documentId: "a1b2c3d4e5d6f7g8h9i0jkl") {
documentId
}
}
如果为你的内容类型启用了国际化(i18n)功能,则可以删除文档的特定本地化版本(请参阅 i18n 文档)。
¥If the Internationalization (i18n) feature is enabled for your content-type, you can delete a specific localized version of a document (see i18n documentation).
媒体文件的修改
¥Mutations on media files
目前,媒体字段上的突变使用 Strapi v4 id 而不是 Strapi 5 documentId 作为媒体文件的唯一标识符。
¥Currently, mutations on media fields use Strapi v4 id, not Strapi 5 documentId, as unique identifiers for media files.
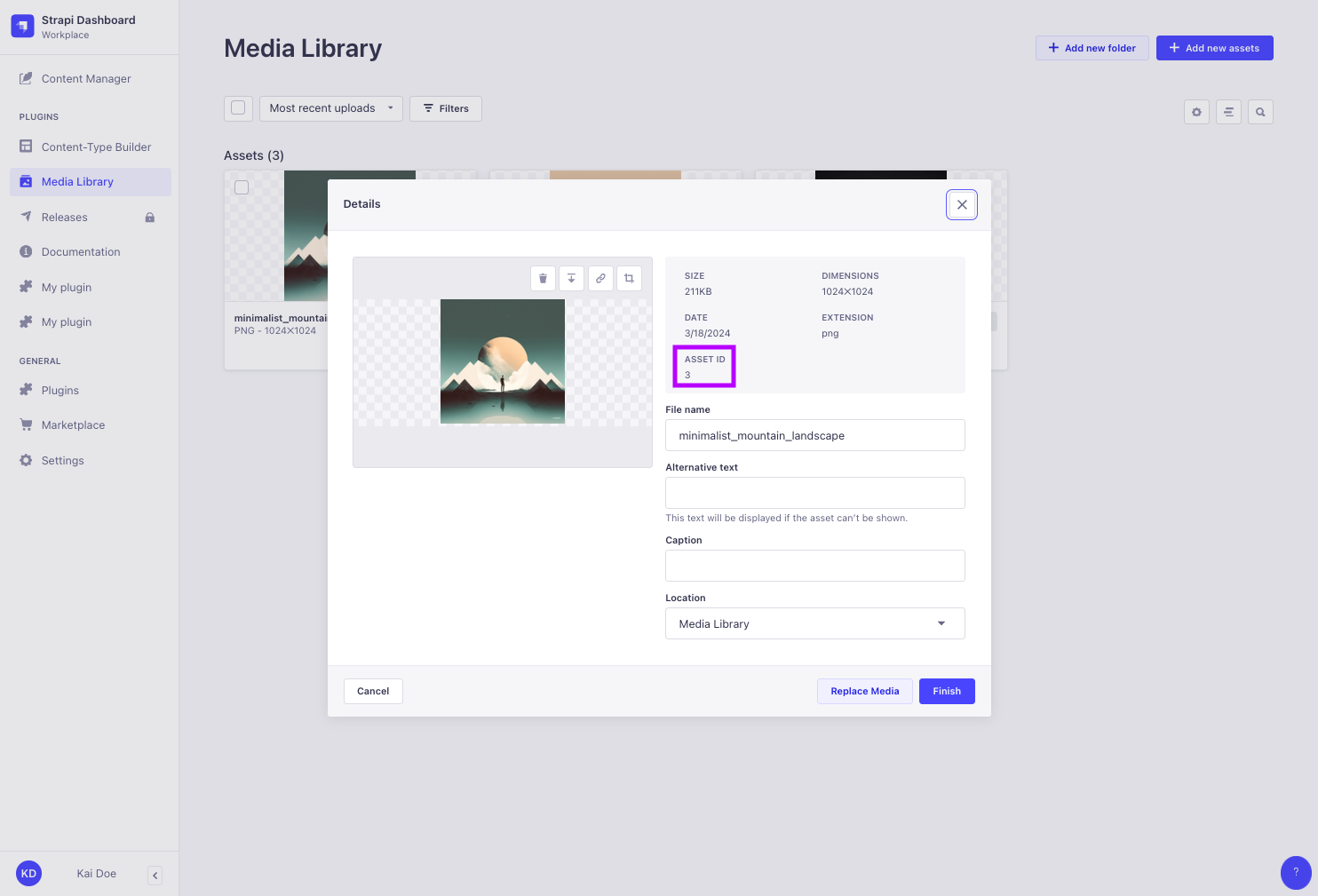
媒体字段突变使用文件 id。但是,Strapi 5 中的 GraphQL API 查询不再返回 id。可以找到媒体文件 id:
¥Media fields mutations use files id. However, GraphQL API queries in Strapi 5 do not return id anymore. Media files id can be found:
-
在管理面板的 媒体库 中,
¥either in the Media Library from the admin panel,
-
或通过发送 REST API
GET请求 填充媒体文件,因为 REST API 请求当前返回媒体文件的id和documentId。¥or by sending REST API
GETrequests that populate media files, because REST API requests currently return bothidanddocumentIdfor media files.
更新已上传的媒体文件
¥Update an uploaded media file
更新上传的媒体文件时,传递媒体的 id(而不是其 documentId)和包含新内容的 info 对象。info 参数将具有特定于媒体文件的关联输入类型。
¥When updating an uploaded media file, pass the media's id (not its documentId) and the info object containing new content. The info argument will has an associated input type that is specific to media files.
例如,如果你的 Strapi 项目包含 "餐厅" 内容类型,你将获得以下内容:
¥For instance, if your Strapi project contains the "Restaurant" content-type, you will have the following:
| 修改 | 争论 | 输入类型 |
|---|---|---|
updateUploadFile | info | FileInfoInput! |
例如,以下示例更新 id 为 3 的媒体文件的 alternativeText 属性:
¥For instance, the following example updates the alternativeText attribute for a media file whose id is 3:
mutation Mutation($updateUploadFileId: ID!, $info: FileInfoInput) {
updateUploadFile(
id: 3,
info: {
alternativeText: "New alt text"
}
) {
documentId
url
alternativeText
}
}
如果上传突变返回禁止访问错误,请确保为上传插件设置了适当的权限(请参阅 用户指南)。
¥If upload mutations return a forbidden access error, ensure proper permissions are set for the Upload plugin (see User Guide).
删除已上传的媒体文件
¥Delete an uploaded media file
删除上传的媒体文件时,传递媒体的 id(而不是其 documentId)。
¥When deleting an uploaded media file, pass the media's id (not its documentId).
mutation DeleteUploadFile($deleteUploadFileId: ID!) {
deleteUploadFile(id: 4) {
documentId # return its documentId
}
}
如果上传突变返回禁止访问错误,请确保为上传插件设置了适当的权限(请参阅 用户指南)。
¥If upload mutations return a forbidden access error, ensure proper permissions are set for the Upload plugin (see User Guide).
过滤器
¥Filters
查询可以接受具有以下语法的 filters 参数:
¥Queries can accept a filters parameter with the following syntax:
filters: { field: { operator: value } }
可以将多个过滤器组合在一起,也可以使用逻辑运算符(and、or、not)并接受对象数组。
¥Multiple filters can be combined together, and logical operators (and, or, not) can also be used and accept arrays of objects.
可以使用以下运算符:
¥The following operators are available:
| 运算符 | 描述 |
|---|---|
eq | 平等的 |
ne | 不等于 |
lt | 少于 |
lte | 小于或等于 |
gt | 比...更棒 |
gte | 大于或等于 |
in | 包含在数组中 |
notIn | 不包含在数组中 |
contains | 包含,区分大小写 |
notContains | 不包含,区分大小写 |
containsi | 包含,不区分大小写 |
notContainsi | 不包含,不区分大小写 |
null | 一片空白 |
notNull | 不为空 |
between | 在。。。之间 |
startsWith | 以。。开始 |
endsWith | 以。。结束 |
and | 逻辑 and |
or | 逻辑 or |
not | 逻辑 not |
{
restaurants(
filters: {
averagePrice: { lt: 20 },
or: [
{ name: { eq: "Pizzeria" }}
{ name: { startsWith: "Pizzeria" }}
]}
) {
documentId
name
averagePrice
}
}
排序
¥Sorting
查询可以接受具有以下语法的 sort 参数:
¥Queries can accept a sort parameter with the following syntax:
-
基于单个值排序:
sort: "value"¥to sort based on a single value:
sort: "value" -
根据多个值进行排序:
sort: ["value1", "value2"]¥to sort based on multiple values:
sort: ["value1", "value2"]
排序顺序可以定义为 :asc(升序,默认,可省略)或 :desc(降序)。
¥The sorting order can be defined with :asc (ascending order, default, can be omitted) or :desc (for descending order).
{
restaurants(sort: "name") {
documentId
name
}
}
{
restaurants(sort: "averagePrice:desc") {
documentId
name
averagePrice
}
}
{
restaurants(sort: ["name:asc", "averagePrice:desc"]) {
documentId
name
averagePrice
}
}
分页
¥Pagination
中继样式 查询可以接受 pagination 参数。结果可以按页或按偏移量分页。
¥Relay-style queries can accept a pagination parameter. Results can be paginated either by page or by offset.
分页方法不能混合。始终使用 page 与 pageSize 或 start 与 limit。
¥Pagination methods can not be mixed. Always use either page with pageSize or start with limit.
按页分页
¥Pagination by page
| 范围 | 描述 | 默认 |
|---|---|---|
pagination.page | 页码 | 1 |
pagination.pageSize | 页面大小 | 10 |
{
restaurants_connection(pagination: { page: 1, pageSize: 10 }) {
nodes {
documentId
name
}
pageInfo {
page
pageSize
pageCount
total
}
}
}
按偏移量分页
¥Pagination by offset
| 范围 | 描述 | 默认 | 最大限度 |
|---|---|---|---|
pagination.start | 起始值 | 0 | * |
pagination.limit | 要返回的实体数量 | 10 | -1 |
{
restaurants_connection(pagination: { start: 10, limit: 19 }) {
nodes {
documentId
name
}
pageInfo {
page
pageSize
pageCount
total
}
}
}
pagination.limit 的默认值和最大值可以是带有 graphql.config.defaultLimit 和 graphql.config.maxLimit 键的 在 ./config/plugins.js 中配置 文件。
¥The default and maximum values for pagination.limit can be configured in the ./config/plugins.js file with the graphql.config.defaultLimit and graphql.config.maxLimit keys.